
I’m currently working on a sentiment analysis project for classifying tweets from the only Danish users of twitter – The politicians!
Using the hashtag #dkpol, Danish party members and their peers tweet political sentiments on Twitter. Sentiment (noun) is an attitude toward something; regard; opinion (Dictionary.com). I’m curious to find out which Danish politicians generally have the more happy opinions about politics. Therefore I’m building a sentiment analysis engine to classify political tweets as either happy or unhappy.
I’ve used the following technologies for this project:
R
Windows Task Scheduler
Azure ML
Twitter API
In addition to this, my brother is involved in coding the front end part of this project in Haskell. All source code is available on GitHub in this repo.
First I need some training data. Generally, it’s better to train on the domain which you’re testing in – so I needed some tweets about politics. I’ve written an R script that uses OAuth to authenticate tweet retrieval on the twitter API (basically all tweets with the hashtag #dkpol). Because using GET SEARCH on the twitter API is limited to retrieving new tweets (within the past week), I’ve scheduled this script to run once a week on my local machine appending new tweets to a csv file containing “happy tweets” and “unhappy tweets” (Windows Task Scheduler).
Once I’ve gotten enough data (not quite there yet! something with not enough politicians or that they have something better to do than tweet all the time?), I coded the sentiments according to their use of emoticons – 🙂 indicated positive sentiment and 🙁 indicated negative sentiment. Then I stripped the tweets of all emoticons to be used in the training data. I also did some cleanup to remove usernames, links and other elements that would disturb my feature hashing (basically finding n-grams in the tweets). My approach kind of corresponds to the procedure outlined in Go, Bhayani & Huang (2009).
Here’s the training experiment I build on Azure:
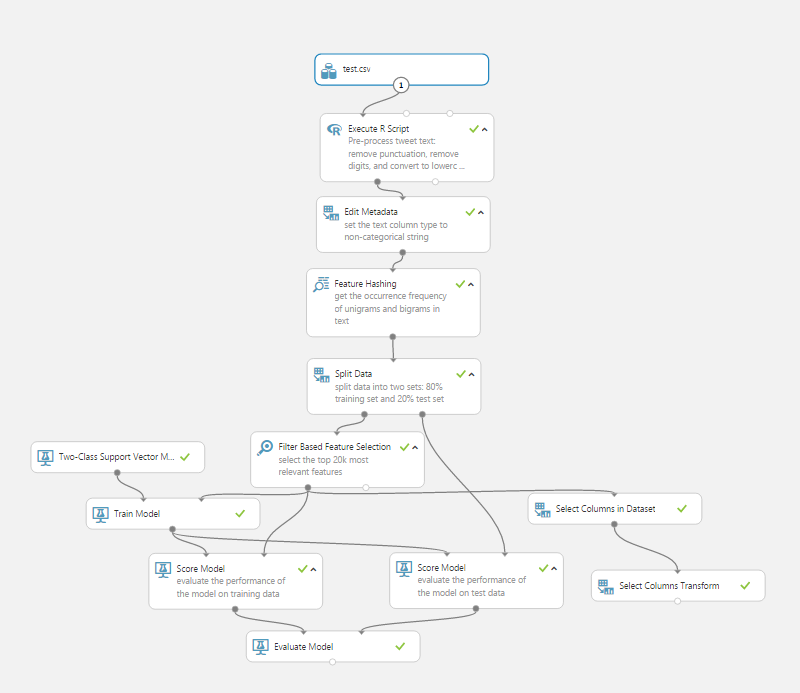
At the time of writing, I’m getting an accuracy score on my model of .643 with a training set of just over 100 tweets. It doesn’t seem impressive, but apparently it’s not too far away from human accuracy as we humans tend to disagree on sentiments a lot (source).
Some realizations I’ve come to during this project:
My sentiment analysis algorithm has no way to detect sarcasm. Danish politicians appear to be very sarcastic on Twitter. It’s really messing up my algorithm…. Solution: Learn new stuff (e.g. Rajadesingan, Zafarani, Liu (2015)) or “get more data” to drown out sarcasm.
Danish politicians don’t tweet enough. I’ll never get the 1.6 mill tweets that Go, Bhayani & Huang (2009) has, but I might not need it given that I’m actually coming up with a pretty decent accuracy.
Examining feature importance of 20.000 n-grams is computationally expensive (like: Don’t do that).